
کامپیوترها با صفر و یک کار میکنند. این جمله رو احتمالاً بارها شنیده یا خونده باشید. معنیش اینه که کامپیوترها چیزی جز 0 و 1 رو متوجه نمیشن. در واقع زبانشون فقط از دو حرف تشکیل شده: 0 و 1. برای همین اگر میخوایم چیزی رو بهشون بفهمونیم، باید با زبان خودشون باهاشون حرف بزنیم. وقتی هم که اونها میخوان با ما ارتباط برقرار کنند، با زبان خودشون با ما ارتباط برقرار میکنند و ما باید بتونیم زبان اونها رو به زبان خودمون «ترجمه» کنیم. این «ترجمه» کردن از زبان خودمون به زبان کامپیوترها و از زبان کامپیوترها به زبان خودمون بهاصطلاح انکود (Encode) و دیکود (Decode) گفته میشه.
یکی از پرکاربردترین و اساسیترین انکود و دیکود کردنها توی دنیای برنامهنویسی مربوط به کاراکترهاست. یک کاراکتر، مثلاً A یا : (دو نقطه)، چطور به باینری (زبان صفر و یک) ترجمه میشه؟ یک ایموجی، مثلاً 😎 به چشم کامپیوترها چطوریه؟ و برعکس، وقتی کامپیوترها معادل باینری حروف و علامتها رو به ما برمیگردونند، از کجا میتونیم بفهمیم که این صفر و یکها معادل چه حرف یا علامتیه؟ اینها سوالات اساسی و مهمیه و دونستن اصول انکود و دیکود کاراکترها و نحوۀ عملکرد یکی از مهمترین استانداردهای این کار، یعنی UTF-8، جالب و خیلی از جاها کمککننده است. نقلقول زیر از یه برنامهنویسه:
I have spent nights at work on problems that could have been resolved with a basic understanding of character encoding.
پس بیاین ببینیم انکود کردن کاراکترها از کجا شروع شده و چه مسیری رو طی کرده که به اینجا رسیده.
زیرتیترهای این مطلب به این ترتیبه:

استاندارد ASCII
کدگذاری حروف و علائم از مسائلی بوده که بشر مدتها باهاش دستوپنجه نرم میکرده. کتابچههای رمزنگاری که در زمان جنگ ازشون برای رمزنگاری یا رمزگشایی پیامها استفاده میشده جوابی به این مشکل بوده. بعدتر در عصر تلگراف نوبت به کد مورس رسید. با ظهور کامپیوترهای اولیه، برنامهنویسها و مهندسها برای ارتباط با کامپیوتر، نمیتونستن مثلاً دستوری شبیه دستور زیر رو مستقیم به کامپیوتر بدن:
fmt.Println(“Hello World”)
چون برای کامپیوتر این کلمات معنادار نبودند و نمیتونست متوجه منظور برنامهنویسها بشه. پس چطور دستورات برنامهنویسی رو به کامپیوترها میفهموندن؟ خب به کمک کارتهای پانچشده! برنامهنویسها دستوراتشون رو مینوشتند، طبق جدول دستورالعمل به باینری ترجمه میکردند و با پانچ کردن کاغذهای مخصوص، اونها رو روی کاغذ میآوردند. بعد هم کاغذها رو به کامپیوترها میدادند و کامپیوترها با خوندن صفر و یکها، دستورات را انجام میدادند.


واقعاً دوران سختی بوده! بالاخره باید فکری برای حل این مشکل برمیداشتند. باید به شکلی، این ترجمۀ عبارتهای انسانی به زبان کامپیوتر رو به خود کامپیوتر میسپردند تا دیگه نیازی به این همه بیگاری نباشه. برای این کار لازم بود که استانداردی تعریف بشه تا بر اساس اون، کامپیوترها بدونن هر حرف یا علامت رو باید چطور به صفر و یک تبدیل کنند.
اَسکی یا ASCII که خلاصۀ عبارت American Standard Code for Information Interchange بهمعنای استاندارد آمریکایی برای تبادل اطلاعاته، در دهۀ 1960 ابداع شد. توی این استاندارد برای کدگذاری کاراکترها از یک بایت استفاده میشد. بهعبارتی در این استاندارد، هر بایت حاوی یک حرف یا علامت بود. البته اسکی از هشت بیتِ داخل یک بایت، فقط از هفتتاش اسفتاده میکنه و بیت آخر (اولین بیت از سمت چپ) رو همیشه صفر در نظر میگیره. توی تصویر زیر، میتونین ببینید که در ASCII هر حرف یا عدد با چه عدد باینری معادله. برای نمونه، حرف A برابر با 01000001 است (که در مقیاس دهدهی خودمون برابر 65 میشه).
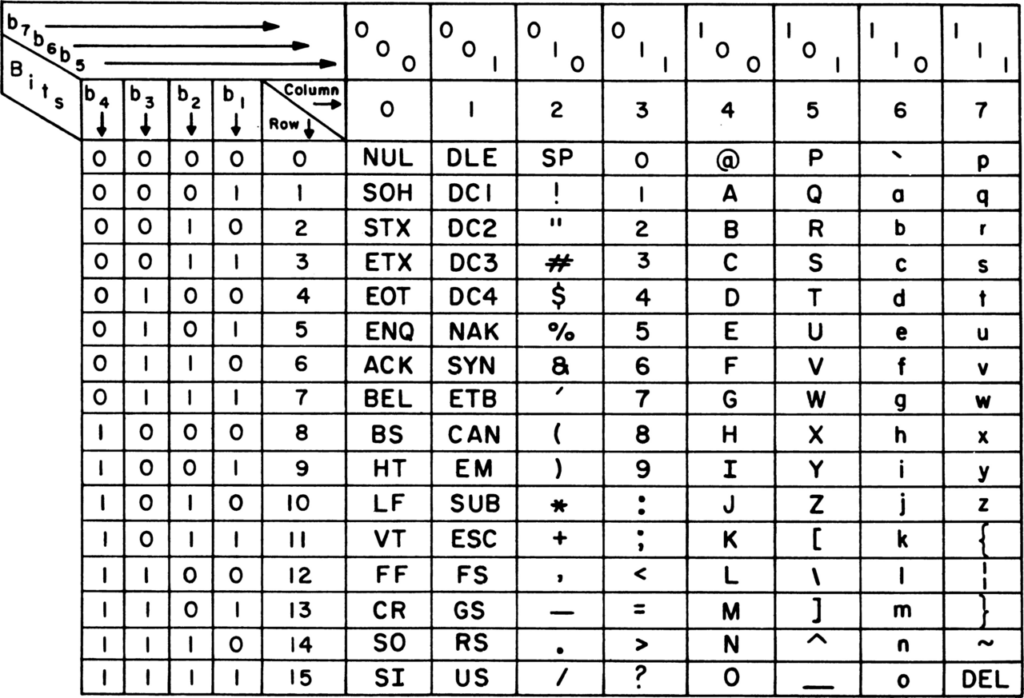
نکته: به عدد متناظر هر کاراکتر در سیستمهای کدگذاری، کد پوینت (Code Point) گفته میشه.
همونطور که گفتم اسکی از 7 بیت برای کدگذاری استفاده میکرده. با 7 بیت میشه 127 عدد مختلف تولید کرد. هر عدد هم معادل یک حرف یا علامت قرار داده شده. این تعداد برای پوشش دادن تمام حروف کوچک و بزرگ انگلیسی و اعداد صفر تا 9 و علامتهای نگارشی و یکسری دستورالعملهای دیگه کافی بوده.
اما آمریکاییها موقع ابداع این استاندارد به فکر بقیۀ مردم جهان نبودند.
با ASCII فقط میشه حروف انگلیسی رو انکود و دیکود کرد. اما همۀ مردم دنیا به این زبان نمینویسند و حرف نمیزنند. کشورهایی که نوشتار لاتینشون متفاوت بود یا زبان بهکل متفاوتی داشتند، از حروفی بهجز حروف عادی انگلیسی استفاده میکردند، در نتیجه ASCII بهتنهایی جوابگوی نیازهاشون نبود.
پس چی کار کردند؟
گفتم که اسکی از هفت بیتِ یک بایت استفاده میکنه. بیت هشتم بیاستفاده و صفره. در نتیجه در جاهای مختلف جهان، استانداردهای محلی مختلفی با استفاده از اون بیت بیاستفاده بهوجود اومد. با کمک اون بیت میشد 128 کاراکتر دیگه رو هم کدگذاری کرد.
بهنظر میرسید مشکل حل شده، اما…
- کامپیوترها به شرق دور و کشورهایی مثل چین وارد شدند. اونها هم میخواستند یه استاندارد محلی برای خودشون شکل بدن، اما از اونجایی که تعداد حروف موردنیازشون خیلی بیشتر از 128تا بود، به مشکل خوردند (میدونین زبان چینی چند حرف داره؟)
- با فراگیر شدن اینترنت، رایانهها به هم متصل شدند. اینجا وجود استانداردهای محلی باعث هرجومرج شد. یک عدد باینری در روسی ممکن بود معادل حرفی خاص باشه، اما وقتی همون کاراکتر وارد کامپیوتر یک فرد با زبان مثلاً یونانی میشد، معادل کاراکتر دیگهای میبود (یا حتی ممکن بود معادل هیچ کاراکتری نباشه). در نتیجه انتقال پیام بهدرستی انجام نمیشد.
این دو مشکل باعث شد که عالمان حوزۀ کامپیوتر به فکر بیفتند و استانداردی جهانی برای انکود و دیکود کردن کاراکترها تدوین کنند.
استاندارد UTF-32
مشکلی که ایجاد شده بود، در اصل از اینجا سرچشمه میگرفت که 7 بیت برای کدگذاری همۀ کاراکترهای موجود کافی نبود. اولین راه حلی که به ذهن میرسه اینه که خب از بیتهای بیشتر (یا در واقع از بایتهای بیشتر) برای کدگذاری استفاده کنیم! راهکار هوشمندانهایه، اما بیدردسر نیست…
یکی از فواید استفاده از تنها یک بایت برای کدگذاری کاراکترها این بود که کامپیوتر میدونست هر کاراکتر صرفاً در یک بایت قرار گرفته، در نتیجه وقتی ده بایت رو کنار هم دریافت میکرد، میدونست که این ده بایت حاوی ده کاراکتر یا کد پوینته. اما اگر از بایتهای بیشتری برای کدگذاری کاراکترها استفاده کنیم، کامپیوتر از کجا بفهمه که هر چندتا از بایتها یک کاراکتره؟ مثلاً اگر بایت اول یک کاراکتر باشه و دو بایت بعدی در کنار هم کد پوینت دیگهای رو نمایش بدن، چی میشه؟ فرض کنید این چهار بایت رو کنار هم داشته باشیم:
01101110 01101001 01101101 01000001
توی سیستم اسکی، این چهار بایت به معنای چهار عدد متفاوتند. از چپ به راست معادل حرف A و m و i و n که در کنار هم Amin رو شکل میدن. اما اگر قرار باشه کدگذاری ما محدود به یک بایت نباشه، کامپیوتر از کجا بدونه که باید مثلاً بایت اول رو تکی در نظر بگیره یا همراه با بایت کناریش یا اصلاً سهتایی و…
کدگذاری UTF-32 برای حل این مشکل راه حلی دمدستی ارائه داد: بیایم طول هر واحد رو از یک بایت به چهار بایت افزایش بدیم. یعنی کلاً به کامپیوتر بگیم که هر چهار بایت در کنار هم رو یک واحد در نظر بگیره و تفسیر کنه. پس اگر قرار بود همون کد 65 برای حرف A رو در سیستم جدید پیادهسازی کنیم، باید به این صورت پیادهاش میکردیم:
01000001 00000000 00000000 00000000
بهنظر میرسید که این سیستم مشکل ما رو حل کرده. با چهار بایت یا در واقع 32 بیت (که پسوند 32 در UTF-32 از اینجا گرفته شده)، میشد تعداد بسیار زیادی عدد تولید کرد. خیلی بیشتر از چیزی که نیاز داشتیم. اما هیچ راه حلی بیهزینه نیست…
اولین مشکل UTF-32 این بود که با ASCII سازگاری نداشت. یعنی اگر متنی با استاندارد ASCII کدگذاری شده بود، دیگه قادر به تفسیر اون با استاندارد UTF-32 نبودیم. دومین مشکل این بود که حجم دادههای کدگذاریشده با UTF-32 چهار برابر دادههایی بود که با ASCII کدگذاری میشدند، حتی اگر توی اون دادهها فقط از حروفی استفاده میشد که توی استاندارد ASCII هم موجود بودند. در واقع این استاندارد استفادۀ بهینهای از فضای ذخیرهسازی نداشت. این شد که ایدۀ UTF-16 ظهور پیدا کرد…
استاندارد UTF-16
شاید با توجه به توضیحاتی که برای UTF-32 دادم، از روی اسم UTF-16 اینطور برداشت کنید که توی این استاندارد هر کاراکتر 16 بیت یا دو بایته. اما اینطور نیست. توی UTF-16 کوچکترین واحد برای ارائۀ یک کد پوینت شامل 16 بیته. اما توی این استاندارد کاراکترها میتونن یک واحدی (16 بیتی) یا دو واحدی (32 بیتی) تعریف بشن. به این صورت که اکثر کاراکترهای متداول با 16 بیت کدگذاری شدهاند. اما اگر قرار به استفاده از کاراکترهای کمتر متداول باشه، بهجای 16 بیت از 32 بیت استفاده میشه. به عبارت دیگه، طول کاراکترها در UTF-16 بهصورت شناور مشخص میشه: یا 16 بیته (2 بایت) یا 32 بیت (4 بایت).
این استاندارد نسبت به UTF-32 مزیت بزرگی داره و اونم اینه که حجم دادهها رو میتونه تا نصف کاهش بده. اما باز هم حداقل دو برابر استاندارد اسکیه. ضمن اینکه همچنان مثل UTF-32 با استاندارد ASCII سازگاری نداره (چون در ASCII کوچکترین واحد برای هر کاراکتر یک بایته و در UTF-16 دو بایت).
اینجا بود که خورههای علوم کامپیوتر به این نتیجه رسیدند که برای باز کردن این گره به کمی خلاقیت بیشتر نیازه. همین شد که UTF-8 به دنیا اومد…
برای کسانی که بیشتر کنجکاون!
قبلاً گفتیم که یکی از مشکلات شناور بودن اندازۀ بایتی کد پوینتها، اینه که کامپیوتر نمیدونه باید چطور بایتها رو تفسیر کنه. پس استاندارد UTF-16 چطور این مشکل رو حل کرده و تونسته اندازۀ هر کد پوینت رو بین دو یا چهار بایت شناور کنه؟ روش جالبی داره.
توی استاندارد UTF-16 یک سری از کاراکترها رو میشه با دو بایت کدگذاری کرد. یعنی برای کاراکترهای پراستفادهتر، اعداد بین 0x0000 تا 0xD7FF و 0xE000 تا 0xFFFF اختصاص داده شده. چون این اعداد بزرگه، در مبنای 16 (هگزادسیمال) به این شکل نوشته میشن. اگر این اعداد رو به مبنای 10 بیاریم، میشه از 0 تا 55295 و از 57344 تا 65535.
اولین سوالی که برای آدم بهوجود میاد اینه که اون بازۀ وسط، بین 55296 تا 57343 چی شدن؟ چرا برای اونا کاراکتر اختصاص ندادن؟ چون اعداد این بازه رزرو شدن و کمک میکنند مشکلی که گفته شد حل بشه! بذارین اول بگم ایدۀ اصلی چیه، بعد توضیح بدم که چطور پیاده میشه.
توی استاندارد UTF-16 کاراکترهایی که کد پوینتهای متناظرشون با دو بایت قابل نمایشند، هیچ مشکلی ندارند. یعنی کامپیوتر دو بایت دو بایت پیش میره و هر دو بایت رو به یک کاراکتر برمیگردونه.
حالا اگر کد پوینتی داشته باشیم که چهار بایتی باشه، باید یه جوری به کامپیوتر بفهمونیم که بهجای دو بایت، چهار بایت رو به یک کاراکتر برگردونه. برای این کار، بهشیوهای که در ادامه توضیح میدم، کد پوینت چهار بایتی موردنظرمون رو تبدیل به دوتا کد پوینت دو بایتی میکنیم که توی اون بازۀ رزرو شده قرار گرفته باشند. در نتیجه هر وقت که کامپیوتر به دو بایتی برسه که مقدارش توی اون بازه باشه، متوجه میشه که این دو بایت رو نباید به تنهایی تفسیر کنه و باید دو بایت بعدی رو هم در نظر بگیره و بعد اینها رو با هم تفسیر کنه.
به این دو کد پوینت دو بایتی که توی اون بازۀ رزروشده قرار دارند، جفتِ جایگزین (Surrogate Pair) میگن. یعنی جفتی که جایگزین کد پوینت اصلی شدند. این کلیت کار بود، اما بذارین بهتون بگم که این کار در واقع چطور انجام میشه.
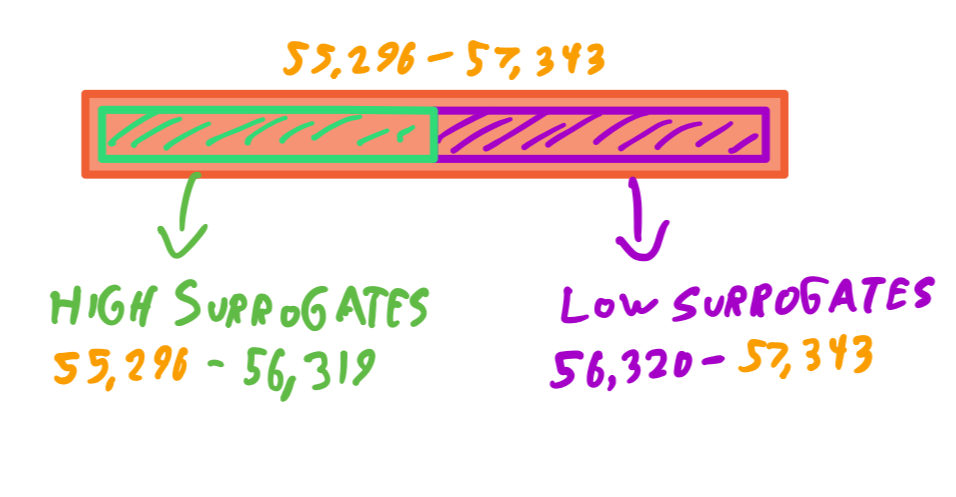
قبل از هر چیز باید بدونین که اون بازۀ رزروشده، از 55296 تا 57343 به دو زیربازه تقسیم میشه:
- بازۀ 55296 تا 56319 که با عنوان High Surrogate شناخته میشه (بیاین بهش بگیم جایگزین اول)
- بازۀ 56320 تا 57343 که با عنوان Low Surrogate شناخته میشه (بیاین بهش بگیم جایگزین دوم)
حالا با در نظر گرفتن این موضوع بیاین در یک مثال عملی، گامبهگام با عملیات تبدیل یک عدد چهار بایتی به یک جفت جایگزین آشنا بشیم.
فرض کنید که ما قصد داریم ایموجی 😎 رو در قالب UTF-16 کدگذاری کنیم:
- در گام اول باید ببینیم کد پوینت متناظر با این ایموجی چیه. با مراجعه به سایت یونیکد، متوجه میشیم که کد پوینت این ایموجی برابر U+1F60E است. عدد بعد از بعلاوه، مقدار هگزادسیمال کد پوینته که معادل دهدهیش میشه 128526. مشخصه که این مقدار رو نمیتونیم با دو بایت (16 بیت) نشون بدیم.
- در گام دوم باید 0x10000 یا معادل دهدهیش 65536 رو از کد پوینت کم کنیم که در مثال ما برابر با 62990 میشه.
62990 = 65536 – 128526
چرا این کار رو میکنیم؟ میخوایم ببینیم چه مقدار از کد پوینتمون رو میتونیم در دو بایت جا بدیم (0x10000 یکی بیشتر از آخرین عددیه که میشه توی دو بایت جا داد).
- در گام سوم باید مقدار باقیمونده رو به باینری تبدیل کنیم و پشتش اونقدر صفر بذاریم تا بیست رقمه بشه. در مثال ما به این شکل میشه:
0b00001111011000001110
- حالا عدد باینری بهدست اومده رو از وسط دو نیم و تبدیل به دوتا باینری دهتایی میکنیم. به این صورت:
0b00001111011000001110
0b0000111101 0b1000001110
که معادل دهدهیشون میشه 61 و 526.
- حالا هر کدوم از اینها رو به عدد شروع بازۀ جایگزین اول و دوم اضافه میکنیم. به این صورت:
55296 + 61 = 55358
56320 + 526 = 56846
و تمام! دو عدد بهدست اومده همون جفت جایگزین ما برای کد پوینت ایموجیمونن. در واقع طبق استاندارد UTF-16 وقتی کامپیوتر با این دو عدد مواجه میشه (که هر کدومشون توی دو بایت جا میشن)، میبینه که توی بازۀ رزروشده قرار دارند، در نتیجه متوجه میشه که باید اونا رو جفتی تفسیر کنه. بعد مسیری برعکس مسیر ما رو طی میکنه تا به کد پوینت موردنظرمون برسه. به همین راحتی، به همین خوشمزگی!
سوال: چرا بازۀ رزروشده رو به دوتا زیر بازه تقسیم کردیم؟ مثلاً چرا هر دو مقدار بهدست اومده رو به ابتدای بازۀ جایگزین اضافه نکردیم؟
فرض کنید اطلاعات از طریق استریم به کامپیوتر شما میرسه و اولین دو بایتیِ ورودی به کامپیوتر توی بازۀ جایگزین قرار داشته باشه. کامپیوتر از کجا باید بفهمه که اون دو بایتِ اوله یا دو بایت دوم؟ حالا که ما دوتا زیربازه داریم، اگر دو بایت در زیربازۀ اول باشه، کامپیوتر متوجه میشه که ابتدای کاراکتر قرار داره و اگر در زیربازۀ دوم باشه، متوجه میشه که وسط کاراکتره و دو بایت بعدی شروع کاراکتر دیگهایه.
نکته: ابداع UTF-16 با چالش دیگهای هم همراه بود که ناشی از معماری متفاوت کامپیوترها در نحوۀ ذخیرهسازی دادهها بود: بیگ اندیَن (Big Endian) و لیتل اندیَن (Little Endian). اما توضیح اینکه اینا چیان و چرا برای UTF-16 چالش ایجاد کردند، از حوصلۀ این مطلب خارجه. برای آشنایی باهاشون این صفحۀ ویکیپدیا رو بخونید که توضیحات خلاصه و مناسبی داره. برای اینکه ببینید چه چالشی ایجاد کردند و چطور این مشکل حل شده، کافیه دربارۀ BOM یا Byte Order Mark جستوجو کنید یا نگاهی به این صفحۀ ویکیپدیا بندازید (متأسفانه مطلب فارسی مناسبی در این زمینه پیدا نکردم).
استاندارد UTF-8

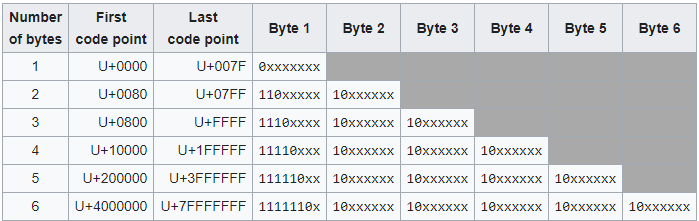
از بین استانداردهای یونیکد، احتمالاً اسم UTF-8 رو بیش از بقیه شنیده باشید. طبیعی هم هست، چون در حال حاضر پراستفادهترین استاندارد یونیکده. توی این استاندارد، همونطور که از اسمش بر میاد، کوچکترین واحد برای هر کد پوینت 8 بیت یا یک بایته و میتونیم از 1 تا 6 بایت برای کدگذاری کد پوینتها استفاده کنیم (هرچند تا الان حداکثر به 4 بایت نیاز داشتیم).
حالا که کوچکترین واحد برای هر کد پوینت 8 بیته، در نتیجه این استاندارد با اسکی سازگاره و اگه دادهای با اون استاندارد کدگذاری شده باشه، بهراحتی با این استاندارد هم تفسیرپذیره. در ضمن مشکل کمبود بیت برای کدگذاری هم نداریم.
اما UTF-8 چطور چالش شناور بودن طول کد پوینت رو حل کرده؟ با راه حلی بسیار خلاقانه و جالب.
اگر کد پوینت ما تک بایتی باشه، پرارزشترین بیت (اولین بیت از سمت چپ) برابر صفر قرار میگیره. اینطوری سازگاری کاملی با سیستم اسکی داریم.
اگر کد پوینت ما بیش از یک بایت باشه، بایتها به دو دسته تقسیم میشن: اولین بایت یا Leading Byte که بیاین بهش بگیم بایت راهبر و سایر بایتها یا Trailing Bytes که بیاین بهشون بگیم بایتهای دنبالهرو.
بایت راهبر به کامپیوتر میفهمونه که کد پوینت انکودشدۀ ما حاوی چند بایته. به این ترتیب که به تعداد بایتهای کد پوینت، ابتدای بایت راهبر عدد یک قراره میگیره و بعد از اون یک بیت برابر صفر میشه. برای نمونه بایت راهبر برای کد پوینتی که سه بایته باید به شکل 1110xxxx باشه و از بیتهای x برای کدگذاری استفاده میشه.
بایتهای دنبالهرو هم همگی با 10 شروع میشن. یعنی ساختار بایتهای دنبالهرو همیشه بهشکل 10xxxxxx است.
جدول زیر میتونه توی فهم بهتر این سیستم کمک کنه.
به همین راحتی! با این سیستم اولاً کاملاً با اسکی سازگاریم، ثانیاً برای زبانهای انگلیسی که توی دنیای کامپیوتر پراستفادهترن، تنها نیازمند استفاده از یک بایتیم (برخلاف UTF-16 که حداقل دو بایته) که در نتیجه مصرف منابع بهتری داریم.
سه نکته:
- علت شروع بایتهای دنبالهرو با 10 اینه که اگر دادهها از وسط یک کاراکتر به کامپیوتر رسید (مثلاً موقع شروع استریم)، کامپیوتر بدونه که بایت دریافتیش یک بایت دنبالهرو است و باید در کنار سایر بایتهای دنبالهرو و با توجه به بایت راهبرش تفسیر بشه.
- با این سیستم حداکثر میتونیم از 6 بایت برای کدگذاری استفاده کنیم (که البته خیلی بیشتر از نیاز ماست و 4 بایت نیاز فعلی ما رو رفع میکنه)، چون اگر بخوایم از 7 بایت استفاده کنیم، بایت راهبر بهشکل 11111110 در میاد که برابر دهدهیش میشه 254 و این عدد برای کاربردهای دیگهای رزرو شده.
- برای بعضی زبانها، استفاده از UTF-16 بهینهتر از UTF-8 است. چون بعضی از کد پوینتهایی که در UTF-16 در دو بایت جا میشن، در UTF-8 در سه بایت قرار میگیرن (دو بایت در UTF-16 شانزده بیت در دسترس برای کدگذاری داره، اما در UTF-8 این عدد برابر یازده بیته).
اما توی سیستم UTF-8 دیکود کردن چطور انجام میشه؟ برای این کار نشانههایی که ابتدای بایتها وجود دارن، چه در بایت راهبر و چه در بایتهای دنبالهرو کنار گذاشته میشن و بیتهای باقیمونده که در واقع برای کدگذاری استفاده شدن بهترتیب از چپ به راست کنار هم قرار میگیرن و یک عدد باینری رو تشکیل میدن. این عدد باینری ما رو به کد پوینت موردنظرمون میرسونه. مثل آبِ خوردن!
یه نکتۀ بهدرد نخور ولی جالب: راب پایک و کن تامسون، خالقان UTF-8، موقع صرف غذا و توی رستوران به ایدۀ اولیۀ این استاندارد سر و شکل دادند و از دستمال کاغذیهای داخل رستوران برای یادداشتبرداری از ایدهشون استفاده کردند! راب پایک داستان خلق این استاندارد رو اینجا نوشته.
امیدوارم با خوندن این مطلب با یونیکد و استانداردهای انکودینگ کاراکترها از جمله UTF-8 و UTF-16 و UTF-32 آشنا شده باشید و البته مثل من در این حین از آشنایی باهاشون لذت برده باشید ^_^
دیدگاهتان را بنویسید